빠른 CPU를 위한 설계 기법
클럭과 코어, 스레드라는 개념을 학습하고, 빠른 CPU를 만드는 설계 기법인 멀티코어와 멀티스레드가 무엇인지 공부해 보자!
클럭
클럭 속도가 높아지면 CPU는 명령어 사이클을 더 빠르게 반복한다. 클럭 속도는 헤르츠(Hz) 단위로 측정한다. 1초에 클럭이 몇 번 반복되는지를 나타내는 것이다. 클럭이 1초에 한번 반복되는 경우 CPU 클럭 속도는 100Hz인 것이다. 하지만 클럭 속도가 높다고 항상 CPU 속도가 빨라지는 것은 아니다.
코어와 멀티코어
클럭 속도를 높이는 방법 외에 CPU 코어와 스레드 수를 늘리는 방법으로 CPU의 성능을 높일 수 있다.
기존에는 CPU는 명령어를 실행하는 부품으로 배웠지만, 오늘날 CPU는 많은 기술 발전 끝에 CPU내부에 명령어를 실행하는 많은 부품을 만들 수 있게 되었다. 그러므로 명령어를 실행하는 부품은 코어라는 단어로 대체되었다. 오늘날 CPU는 ‘명령어를 실행하는 부품’에서 ‘명령어를 실행하는 부품을 여러 개 포함하는 부품’으로 명칭의 범위가 확장되었다.

코어를 여러 개 포함하고 있는 CPU를 멀티코어 CPU 또는 멀티코어 프로세스라고 부른다.
CPU내에 여러 명의 일꾼이 있는 개념이다. 코어 수가 1개인 경우 싱글코어, 2개인 경우 듀얼코어, 3개인 경우 트리플코어, 4개인 경우 쿼드코어, 6개인 경우 헥사코어, 8개인 경우 옥타코어라고 부른다.
다만 코어가 늘어난다고 해서 반드시 CPU의 연산 속도가 빨라지는 것은 아니다. 학교 모둠 수업만 생각해 봐도 4인 1조 인 팀보다 6인 1조 인 팀이 항상 우수한 성적을 내는 게 아닌 것과 같다.
스레드와 멀티스레드
스레드는 아주 아주 아주 중요한 개념이다. CPU의 멀티스레드 개념에서도 나오기에 정확히 이해하고 넘어가자!
스레드의 사전적 의미는 ‘실행 흐름의 단위’이다. 이러한 스레드는 CPU에서 사용되는 하드웨어적 스레드와 프로그램에서 사용되는 소프트웨어적 스레드로 구분할 수 있다.
하드웨어적 스레드
스레드를 하드웨어적으로 정의하면 ‘하나의 코어가 동시에 처리하는 명령어 단위'이다.
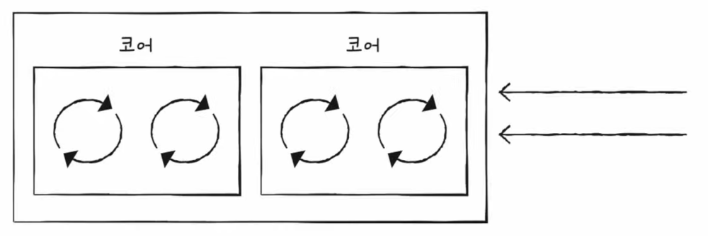
해당 이미지는 2 코어 4 스레드이다. 명령어를 실행하는 부품은 2개이며 한 번에 4개의 명령어를 처리할 수 있는 것이다. 이처럼 하나의 코어로 여러 명령어들을 동시에 처리하는 CPU를 멀티스레드 프로세서 또는 멀티스레드 CPU라고 한다.
소프트웨어적 스레드
소프트웨어적으로 적으로 정의된 스레드는 ‘하나의 프로그램에서 독립적으로 실행되는 단위’를 의미한다.
일반적으로 운영체제를 공부할 때 나오는 스레드의 개념은 소프트웨어적 스레드이다.

하나의 프로그램은 실행되는 과정에서 한 부분만 실행될 수도 있지만, 프로그램의 여러 부분이 동시에 수행될 수도 있다. 위의 이미지의 경우 동시에 수행할 수 있는 경우이다. 예를 들어, 1) 사용자가 입력한 글을 보여주고, 2) 입력한 글의 맞춤법이 맞는지 확인하고, 3) 입력한 내용을 저장하는 경우 멀티 스레드는 반드시 필요하다.
멀티스레드 프로세서
소프트웨어적으로 정의된 스레드는 스레드, CPU에서 사용되는 스레드는 하드웨어 스레드로 정의하고 넘어가겠다. 멀티스레드 프로세서는 하나의 코어로 여러 명령어를 동시에 처리하는데 어떻게 가능할까?
멀티스레드 프로세서의 가장 큰 핵심은 레지스터이다. 하나의 코어로 여러 명령어를 동시에 처리하도록 하기 위해서는 프로그램 카운터, 스택 포인터, 메모리버퍼 레지스터, 메모리주소 레지스터와 같이 하나의 명령어를 처리하기 위해 꼭 필요한 레지스터가 많다.
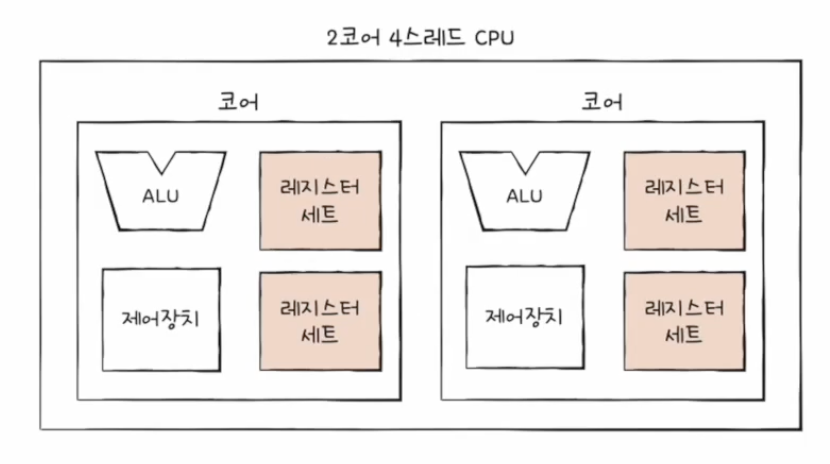
위의 이미지에서 ALU와 제어장치가 두 개의 레지스터 세트에 저장된 명령어를 해석하고 실행하면 하나의 코어에서 두 개의 명령어가 동시에 실행된다.
2 코어 4 스레드 CPU는 한 번에 네 개의 명령어를 처리할 수 있는데 프로그램 입장에서 보면 한 번에 하나의 명령어를 처리하는 CPU가 4개인 것처럼 보인다. (뭐지..? 코어가 4개인 건가??) 그래서 하드웨어적 스레드를 논리 프로세서라고 부르기도 한다.
정리하자면!~ 코어는 명령어를 실행할 수 있는 하드웨어 부품이고, 스레드는 명령어를 실행하는 단위이다.
멀티코어 프로세서는 명령어를 실행할 수 있는 하드웨어 부품이 CPU안에 두 개 이상 있는 CPU를 의미하고
멀티스레드 프로세서는 하나의 코어로 여러 개의 명령어를 동시에 수행할 수 있는 CPU를 의미한다.
명령어 병렬 처리 기법
빠른 CPU를 만들기 위해서 높은 클럭 속도, 멀티코어, 멀티 스레드를 지원하는 CPU를 만드는 것도 중요하지만, CPU가 놀지 않고 시간을 알뜰하게 쓰며 작동하는 것도 중요하다.
CPU를 쉬지 않고 작동시키는 방법인 명령어 파이프 처리 기법을 알아보자!
명령어 파이프 처리 기법은 명령어 파이프 라이닝, 슈퍼스칼라, 비순차적 명령어 처리. 이렇게 3가지가 있다.
명령어 파이프 라인
명령어 파이프 라인을 이해하기 위해서는 하나의 명령어가 처리되는 과정을 시간 간격으로 나누어 봐야 한다. 이러한 시간 간격은 클럭 단위로 나누는 것이 일반적이다.
- 명령어 인출
- 명령어 해석
- 명령어 실행
- 결과 저장
위의 4가지 단계가 정답이 아니며, 전공 서적에 따라 달라질 수도 있다고 하니 대략적인 느낌만 가져가자!
위의 4가지 단계가 겹치지만 않는다면, CPU는 각 단계를 동시에 수행할 수 있다. 예를 들어, CPU가 명령어를 인출하는 동안 다른 명령어를 실행할 수 있고, 다른 명령어를 실행하는 동안 연산 결과를 저장할 수 있다.


공장 생산라인과 같이 명령어를 명령어 파이프라인이라고 부르며, 동시에 처리하는 기법을 명령어 파이프라이닝이라고 부른다. 하지만! 파이프라이닝이 모든 경우에서 가능한 것은 아니다. 이러한 상황을 파이프라인 위험이라고 부르는데, 파이프라인 위험에는 3가지 종류가 있다. 1) 데이터 위험, 2) 제어 위험, 3) 구조적 위험이 대표적이다.
데이터 위험
데이터 위험은 명령어 간 데이터의 의존성 문제로 발생한다. 모든 명령어를 동시에 처리할 수 없다는 의미이다.
명령어 1: R1 ← R2 + R3 // R2 레지스터 값과 R3 레지스터 값을 더한 값을 R3에 저장
명령어 2: R4 ←R1 + R5 // R1 레지스터 값과 R5 레지스터 값을 더한 값을 R5에 저장
해당 경우 명령어 1을 수행해야 명령어 2를 수행할 수 있다. 이처럼 데이터 의존적인 두 명령어를 무작정 동시에 실행하려고 하면 파이프라인이 제대로 작동하지 않는다. 이를 데이터 위험이라고 한다.
제어 위험
제어 위험은 분기 등으로 인한 ‘프로그램 카운터의 갑작스러운 변화’에 의해 발생한다. 일반적으로 프로그램 카운터는 ‘현재 실행 중인 명령어의 다음 주소’로 갱신된다. 하지만! 실행 흐름이 바뀌어 명령어가 실행되던 프로그램 카운터의 값이 갑자기 변하면 명령어 파이프라인에 미리 가져와서 작업 중이던 명령어는 쓸모가 없게 되는 것이다. 이를 제어 위험이라고 한다.
이를 해결하는 기술이 분기 예측이다. 분기 예측은 프로그램이 어디로 분기할지 미리 예측한 후 그 주소를 인출하는 것이다.
구조적 위험
구조적 위험은 명령어들을 겹쳐 실행하는 과정에서 서로 다른 명령어가 동시에 ALU, 레지스터와 같은 CPU부품을 사용할 때 발생한다. 구조적 위험은 자원 위험이라고 부르기도 한다.
슈퍼스칼라
CPU 내부에 여러 개의 명령어 파이프라인을 포함한 구조를 슈퍼스칼라라고 한다.
명령어 파이프 라인을 하나만 두는 것이 공장 생산 라인을 한 개 두는 것과 같다면, 슈퍼스칼라는 공장 생산 라인을 여러 개 두는 것과 같다.

슈퍼스칼라 구조로 명령어 처리가 가능한 CPU를 슈퍼스칼라 프로세서 혹은 슈퍼스칼라 CPU라고 부른다. 슈퍼스칼라 프로세서는 이론적으로 파이프라인 개수에 비례해 프로그램의 처리 속도가 빨라지지만, 예상치 못한 문제를 만나는 경우 반드시 비례해서 빨라지지는 않는다.
비순차적 명령어 처리
비순차적 명령어 처리는 전공책에 나오는 개념은 아니라고 한다. 일종의 합법적 새치기 개념이다.
이름에서도 알 수 있듯 명령어들을 순차적으로 실행하지 않는 기법이다.
앞서 배웠던 명령어 파이프라이닝, 슈퍼스칼라 기법은 모두 순차적인 처리 기법이다.
CISC와 RISC
파이프라이닝과 슈퍼스칼라 기법을 효과적으로 사용하기 위해서는 CPU가 인출하고 해석하고 실행하는 명령어가 파이프라이닝하기 쉽게 생겨야 한다. 파이프라이닝하기 쉬운 명령어가 뭘까?
CPU의 언어인 ISA와 각기 다른 성격의 ISA를 기반으로 설계된 CISC와 RISC를 살펴보자!
명령어 집합
CPU는 다양한 제조사가 있고 각 CPU마다 규격과 기능이 다른데, CPU가 이해하는 명령어들이 똑같이 생겼을 리는 없다. CPU가 이해할 수 있는 명령어들의 모음을 명령어 집합 또는 명령어 집합구조(ISA)라고 한다. 즉 CPU마다 ISA가 다를 수 있다는 것이다.
ISA가 다르다는 것은 CPU가 이해할 수 있는 명령어가 다르다는 것이고, 명령어가 달라지면 어셈블리어도 달라진다. 같은 소스코드로 만들어졌다 할지라도 ISA가 다르면 CPU가 이해할 수 있는 명령어와 어셈블리어가 모두 달라진다는 것을 알 수 있다.
ISA는 CPU의 언어임과 동시에 CPU를 비롯한 하드웨어가 소프트웨어를 어떻게 이해할지에 관한 약속이다.
CISC
CISC는 Complex Instruction Set Computer의 약자이다. CISC란 말 그대로 복잡하고 다양한 명령어들을 활용하는 CPU기반 설계 방식인 것이다. 명령어의 크기와 형태가 다양한 가변 길이 명령어를 활용하는 것도 특징이다. CISC는 다양하고 강력한 기능의 명령어 집합을 활용하는데 이는 상대적으로 적은 수의 명령어로 프로그램을 실행할 수 있다는 것이다.
적은 수의 명령어로 프로그램을 동작시킬 수 있다는 것은 장점이지만, 명령어가 크고 복잡하기 때문에 명령어를 실행하기까지 시간이 일정하지 않다는 것이다. 명령어의 수행길이가 가지각색이기 때문에 파이프라인도 효율적으로 명령어를 처리할 수 없게 되는 것이다.
정리하자면, CISC 명령어 집합은 복잡하고 다양한 기능을 제공하기에 적은 수의 명령으로 프로그램을 동작시키고 메모리를 절약할 수 있지만, 명령어의 규격화가 어려워 파이프라이닝이 어렵다는 단점이 있다.
RISC
RISC는 Reduced Instruction Set Computer의 약자이다. CISC의 한계를 개선한 것이다.
- 원활한 파이프라이닝을 위해 명령어의 길이와 수행시간이 짧아야 하고 규격화되어 있어야 한다.
- 자주 쓰이는 명령어 위주로 기본적인 명령어를 작고 빠르게 만들어야 한다.
이러한 특징을 고려하여 RISC는 고정 길이 명령어를 사용한다. 또한 CISC에 비해 명령어의 종류가 적으며 짧고 규격화된 명령어를 갖는다. 1 클럭 내외로 실행되는 명령어를 지향한다는 특징이 있다.
RISC는 메모리에 직접 접근하는 명령어를 load와 store. 2개로 제한하므로 CISC보다 주소 지정 방식의 종류가 적은 경우가 많다.
RISC는 메모리 접근을 단순화, 최소화하는 대신 레지스터를 적극적으로 활용한다. 그렇기 때문에 CISC보다 레지스터를 이용하는 연산이 많고 일반적인 경우보다도 범용 레지스터를 많이 사용한다. 하지만 CISC보다 명령어의 개수가 적기 때문에 CISC에 비해 많은 명령어로 프로그램을 작동시킨다.
| CISC | RISC |
| 복잡하고 다양한 명령어 | 단순하고 적은 명령어 |
| 가변 길이 명령어 | 고정 길이 명령어 |
| 다양한 주소 지정 방식 | 적은 주소 지정 방식 |
| 프로그램을 이루는 명령어의 수가 적음 | 프로그램을 이루는 명령어의 수가 많음 |
| 여러 클럭에 걸쳐 명령어 수행 | 1클럭 내외로 명령어 수행 |
| 파이프라이닝하기 어려움 | 파이프라이닝하기 쉬움 |
'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] Chapter 07 보조기억장치 (3) | 2023.12.05 |
|---|---|
| [컴퓨터 구조] Chapter 06 메모리와 케시 메모리 (1) | 2023.12.02 |
| [컴퓨터 구조] Chapter 04 CPU의 작동원리 (1) | 2023.11.13 |
| [컴퓨터 구조] Chapter 03 명령어 (0) | 2023.11.11 |
| [컴퓨터 구조] Chapter 02 데이터 (0) | 2023.11.07 |



