🗓️ 23.10.16
- Memory Protection
Page table의 각 entry마다 아래의 bit를 둔다.
• Protection bit
page에 대한 접근 권한 (오직 읽을 수만 있거나/ 쓸 수도 있거나)
• Valid-invalid bit
valid는 해당 주소의 frame에 그 프로세스를 구성하는 유효한 내용이 있음을 뜻함 (접근 허용)
invalid는 해당 주소의 frame에 유효한 내용이 없음을 뜻함 (접근 불허)
- Inverted Page Table

”공간을 줄이기 위해 사용한다 “는 것을 알아두자
Inverted Page Table은 가상 메모리 주소와 물리 메모리 주소를 연결하는 데이터 구조이다. 이 테이블은 프로세스가 사용하는 페이지를 식별하고, 해당 페이지가 물리 메모리 어디에 위치하는지를 나타낸다. 기존의 페이지 테이블과 달리, 모든 프로세스를 위한 단일 테이블을 사용하므로 공간을 절약할 수 있다는 장점이 있다.
하지만 이 방식은 빠른 주소 변환을 위해 추가 작업이 필요하며, 프로세스 수가 많거나 빈번하게 변경되는 경우 오버헤드가 발생할 수 있다.
page table이 큰 이유
모든 process 별로 그 logical address에 대응하는 모든 page에 대해 page table entry가 존재한다.
- Shared page
Shared Page는 여러 프로세스가 같은 물리 메모리 페이지를 공유하는 메모리 공유 기법이다.
여러 프로세스가 동일한 내용을 읽거나 쓸 때, 물리 메모리에 하나의 페이지만 유지하면 된다. 이로써 메모리 사용량을 절감할 수 있다.
- Inverted Page Table와 Shared page 비교
Inverted Page Table은 메모리 주소 변환에 사용되는 테이블 구조이며, Shared Page는 여러 프로세스가 동일한 메모리 페이지를 공유하여 메모리 사용을 줄이는 방법이다.
- Segmentation
프로그램은 의미 단위인 여러 개의 segment로 구성된다. 작게는 프로그램을 구성하는 함수 하나하나를 세그먼트로 정의하기도 하며 크게는 프로그램 전체를 하나의 세그먼트로 정의하기도 한다. 일반적으로는 code, data, stack 부분이 하나씩의 세그먼트로 정의된다.
🗓️ 23.10.17
어제 한 거 복습했습니다.
🗓️ 23.10.18
- Segmentation Hardware
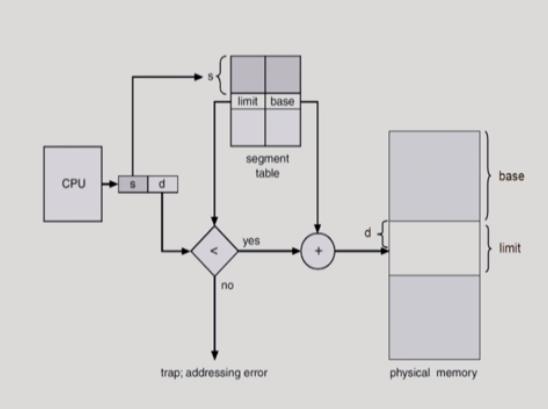
physical memory의 영역보다 offset의 값이 크다면 문제가 발생한다.
문제가 발생한 경우 trap: addressing error로 화살표가 향하는 것을 알 수 있다.
- Segmentation Architecture
Logical address는 다음의 두 가지로 구성된다.
• Segment-table base register(STBR)
물리적 메모리에서의 segment table의 위치
• Segment-table length register(STLR)
프로그램이 사용하는 segment의 수
- Example of Segmentation
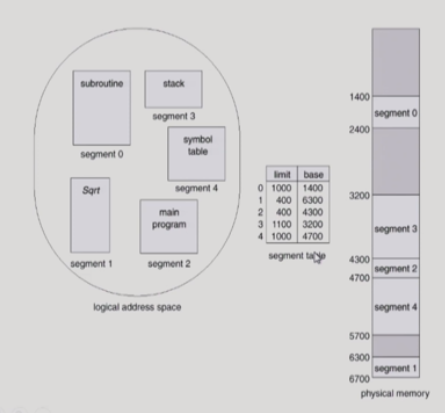
paging의 경우 개수가 많아 공간 낭비가 심하지만,
segmentation 기법의 경우 개수가 많지 않아 공간 낭비가 덜하다는 특징이 있다.
공유 혹은 보안의 작업을 하는 경우 의미단위로 나누는 Segment를 활용하는 것이 훨씬 효율적이다.
반면 동일한 크기단위로 값을 나누는 경우, 같은 크기로 나뉘는 Paging 기법을 사용하는 것이 더 효율적이다.
* 각각의 segment의 경우 물리적 위치의 시작위치가 번지수에 맞게 그림에 위치한 것을 알 수 있다.
- Sharing of Segments

0번 segment의 경우 해당 프로세스 각각에서 물리적 위치의 경우에도 같은 위치에 존재함을 알 수 있다.
0번의 경우 shared이기 때문에.
반면 private의 경우 각각의 주소값을 갖고 있는다는 특징이 있다.
- Segmentation with Paging
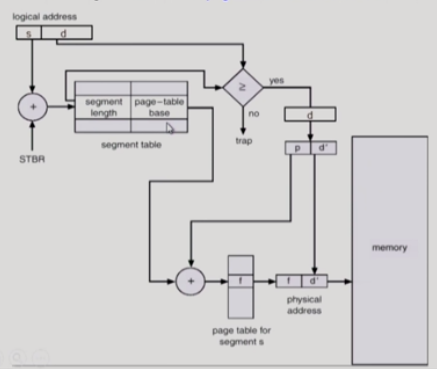
pure segmentatiom과의 차이점
segment-table entry가 segment의 base address를 가지고 있는 것이 아니라 segment를 구성하는 page table의 base address를 갖고 있다는 것.
메모리 단위의 경우 물리적인 단위로 페이지에 올라가기 때문에 allocation이 발생하지 않고,
의미 단위의 경우 page 레벨에서 해주기 때문에 2가지 방법의 장점을 모두 얻을 수 있는 것이다.
segmentation 단위에서 주소변환을 해주고 도출된 각각의 주소값(시작위치)을 넘겨받는 것.
🗓️ 23.10.19
- Demand Paging
-실제로 필요할 때 page를 메모리에 올리는 것
<이를 통해 얻는 효과>
필요한 것만 올리기 때문에!!
I/O 양의 감소
Memory 사용량 감소
빠른 응답 시간
더 많은 사용자 수용
- Valid / Invalid bit의 사용
Invalid의 의미
• 사용되지 않은 주소 영역인 경우
• 페이지가 물리적 메모리에 없는 경우
• 처음에는 모든 page entry가 invalid로 초기화
address transiation 시에 invalid bit이 set 되어 있으면 "page fault"
"page fault"란? 요청한 page가 메모리에 없는 경우를 의미한다.

위의 사진의 경우 물리적 메모리에 올라간 경우 valid에 올라간 걸 알 수 있고,
메모리에 올라가지 않은 경우 디스크에 올라간 것을 알 수 있다.
- Page Fault
invalid page를 접근하면 MMU가 trap를 발생시킨다.
Kernel mode로 돌아가서 page fault handler가 invoke 된다.
다음과 같은 순서로 Page fault를 처리하는데,
해당 페이지를 disk에서 memory로 읽어오고, 해당 프로세스가 CPU를 잡고 다시 running 하는 것.

- Free frame이 없는 경우
- Page replacement
어떤 frame를 뺴앗아올지 결정해야 한다.
- Optimal Algorithm
가장 먼 미래에 참조되는 page를 replace.
미래의 것을 알 수는 없지만 안다는 가정하에 운영하는 것이다.
그렇다면, 미래의 참조를 어떻게 아는가?
Offline algorithm을 통해 알 수 있다.
- FIFO(First In First OUT) Algorithm
먼저 들어온 것을 먼저 내쫓음
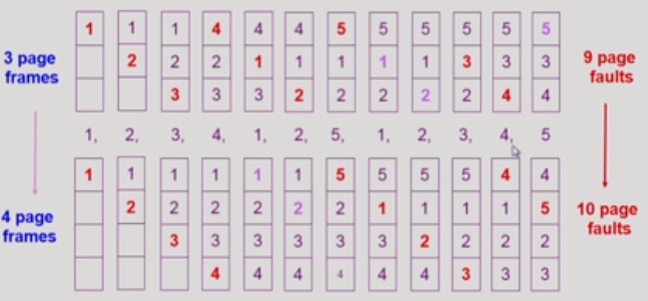
메모리 크기를 늘려줘도.. 성능이 나빠지는 경우가 발생하기도 함
- LRU(Least Recently Used) Algorithm
가장 오래전에 참조된 것을 지움
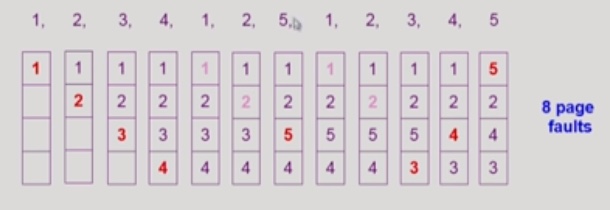
- LFU(Least Frequently Used) Algorithm
과거 참조 횟수가 많은 페이지의 경우 혹시 모르니까 남겨두자..
참조 횟수가 같은 경우, 어떤 걸 쫓아낼지 명시하진 않았지만, 그래도 그나마 오래된 걸 지우는 것
🗓️ 23.10.20
- 다양한 캐슁 환경
캐슁 기법
한정된 공간에 요청된 데이터를 저장해 두었다가 후속 요청 시 캐시로부터 직접 서비스하는 방식이다.
paging system 외에도 cache memory, buffer cashing, Web caching 등 다양한 분야에서 사용된다.
캐시 운영의 시간 제약
교체 알고리즘에서 삭제할 항목을 결정하는 일에 지나치게 많은 시간이 걸리는 경우 실제 시스템에서 사용할 수 없음
- Clock Algorithm

LRU의 근시 알고리즘이다.
NRU(Not Recently Used)
운영체제는 가장 오래전에 참조된 페이지를 알 수 없으므로, 대신 최근에 사용되지 않은 페이지를 쫓아낸다.
• reference bit을 사용해서 교체 대상 페이지를 선정한다.
• reference bit이 0인 것을 찾을 때까지 포인터를 하나씩 앞으로 이동한다.
• 포인터를 이동하는 중 reference bit 1은 모두 0으로 바꾼다.
• reference bit이 0인 것을 찾으면 그 페이지를 교체한다.
reference bit이 0이라는 것은 시곗바늘이 한 바퀴 돌아오는 동안 그 페이지에 대한 참조가 없었다는 것을 의미한다.
reference bit이 1이라는 것은 시곗바늘이 한 바퀴 돌아오는 동안 그 페이지에 대한 참조가 적어도 한 번은 있었다는 것을 의미한다.
페이지가 read가 아닌 write로 참조되는 경우, 하드웨어가 modified bit을 1로 세팅한다.
어떤 페이지를 쫓아낼 때 그 페이지의 modified bit이 0이라면, 그 페이지는 backing store에서 물리적 메모리로 올라온 이후로 write가 발생하지 않은 것이다. 그래서 이 경우 이미 같은 copy가 backing store에 있으므로 그냥 쫓아내기만 하면 된다.
반면 쫓아내고자 하는 페이지의 modified bit이 1이라면, 그 페이지는 물리적 메모리로 올라온 이후로 적어도 한 번은 CPU에서 write를 한 것이다. 이 페이지는 내용이 수정되었으므로, 쫓아낼 때 backing store에 수정된 내용을 반영한 후에 쫓아내야 한다.
- Page Frame의 Allocation
Allocation problem: 각 process에 얼마만큼의 page frame을 할당할 것인가?
Allocation의 필요성
메모리 참조 명령어 수핼 시 명령어, 데이터 등 여러 페이지 동시 참조
즉, 적당히 메모리를 나눠주자는 것이다. A라는 프로그램에는 어느 정도 주고, B라는 프로그램에는 어느 정도 주고.. 하는 식으로 프로그램의 크기에 비례해서 주는 것!
- Thrashing
프로그램에 너무 적은 양만 할당해 주어 계속해서 page fault가 발생하는 경우를 의미한다.

메모리를 사용하는 프로그램이 많아지는 경우, CPU Utilization 이 오르다가 뚝 떨어지는 경우가 발생하는데, 해당 경우가 Thrashing이다. 한 번에 많이 메모리를 사용하는 프로그램의 수가 많아지면 각각의 프로그램은 적은 양의 메모리를 할당받게 되어 시스템이 비효율적으로 되는 상황이 발생하는 것이다.
(이걸 해결해 주는 게 Working-Set Model이다..)
- Working-Set Model
프로세스는 특정 시간 동안 일정 장소만을 집중적으로 참조한다.
집중적으로 참조되는 해당 page들의 집합을 locally set이라고 한다.
Working-Set Model은 Locality에 기반하여 프로세스가 일정 시간 동안 원활하게 수행하기 위해 한꺼번에 메모리에 올라와 있어야 하는 page들의 집합이라고 할 수 있다.
- PFF (Page-Fault Frequency) Scheme

page-fault rate의 상한 값과 하한값을 두는 것이다.
page-fault rat이 상한 값을 넘으면 frame을 더 할당하고
반대로 page-fault rat이 하한값 이하이면 할당 frame를 줄이는 것이다.
Page Size의 결정
Page size를 감소시키면!
페이지 수가 증가한다.
페이지 테이블 크기가 증가한다.
Internal fragmentation이 감소한다.
필요한 정보만 메모리에 올라와 메모리 이용이 효율적이게 된다.
🗓️ 23.10.21
- File and File System
File
일반적으로 비휘발성의 보조기억장치인 하드디스크에 저장한다. File는 저장 용도로 쓰이는 것에 그치지 않는데, 운영체제는 다양한 저장장치를 file이라는 동일한 논리적 단위로보게 해준다. create, read, write, reposition, delete, open, close 등 다양한 Operation이 존재한다.
File attribute(혹은 파일의 metadata)
파일 자체의 내용이 아니라, 파일을 관리하기 위한 각종 정보들을 의미한다. 파일의 이름, 유형, 저장된 위치, 파일 사이즈 등이 해당한다. 접근 권한(읽기/쓰기/실행), 시간(생성/변경/사용), 소유자 등이 해당한다
File system
운영체제에서 파일을 관리하는 부분으로 파일 및 파일의 메타데이터, 디렉터리 등을 관리한다. 어떻게 파일을 저장하고 보호할지 결정하는 것.
- Directory and Logical Disk
Directory
파일의 메타데이터 중 일부를 보관하고 있는 일종의 특별파일이다. 그 디렉터리에 속한 파일 이름과 파일 atribute들. 파일을 찾거나, 만들거나, 삭제하거나 혹은 파일 이름을 재정의하거나..
Parition
하나의(물리적) 디스크 안에 여러 파티션을 두는 게 일반적인데, 이는 논리적 디스크에 해당한다. 경우에 따라서는 여러 개의 물리적 디스크를 합쳐 하나의 논리적 디스크로 만들기도 한다.
- Open()
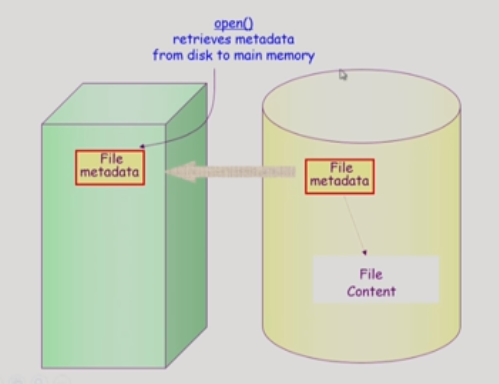
파일을 오픈하면 해당 메타데이터가 메모리에 올라가게 된다.

좌측의 경우 논리적 메모리에 해당하는 부분이다.
실제 디스크에 해당하는 부분인 오른쪽의 경우 root의 metadata에 접근해 실제 위치 값을 알 수 있는 것이다.
- File Proection
각 파일에 대해 누구에게 어떤 유형의 접근을(read/write/excution)을 허락할 것인가?
• Access control Matrix
행렬을 활용하는 것. 표를 활용하여 각 사용자와 권한을 체크하는 것이다.
행렬의 모든 칸을 만드는 것은 비효율적이다..
위 방법의 경우 2가지로 나눌 수 있는데,
1) Access control list 방법은 파일별로 누구에게 어떤 접근 권한이 있는지 표시하는 것이고
2) Capability 방법은 사용자별로 자신이 접근 권한을 가진 파일 및 해당 권한을 표시하는 것이다.
• Grouping
전체 user를 owner, group, public의 세 그룹으로 구분하는 방법이다.
각 파일에 대해 세 그룹의 접근 권한을 3비트씩 표시하는 것이다.
예를 들면, 블로그 운영을 할 때 나만 보기, 서로 이웃 보기, 전체 보기 방식이 이에 해당한다.
• Password
파일마다 password를 두는 방법으로 디렉터리 파일에 두는 방법도 가능하다.
그러나 각각의 파일에 대해 password를 설정하는 것은 효율적인 방법은 아니다.
- Access Methods
시스템이 제공하는 파일 정보의 접근 방식이다.
• 순차 접근(sequential access)
카세트테이프를 사용하는 방식처럼 접근
읽거나 쓰면 offset은 자동적으로 증가
• 직접 접근 (direct access, random access)
LP 레코드 판과 같이 접근하도록 함
파일을 구성하는 레코드를 이미의 순서로 접근할 수 있음
👨💻
지금 강의를 듣고, 정리하는 시간은 23년 10월 20일 새벽 2시 05분이다. 평소에는 작은 휴대폰화면과 휴대폰을 활용해 타자를 치며 힘겹게 공부했는데, 싸지방에서 컴퓨터로 강의를 듣고 정리하니 너무 좋다.. 군대에 들어오기 전 나의 환경이 공부하기에 얼마나 좋았던 건지 다시 생각할 수 있었다. 이렇게라도 공부할 수 있다니 행복한 군생활이다ㅋㅋ 전역 때까지 지금의 마음가짐을 갖고 앞으로 정진할 수 있도록!
🗓️ 23.10.22
- Allocation of File Data in Disk
디스크에 파일을 저장하는 방법은 아래의 3가지 방법이 있다.
보통 동일 단위의 섹터 단위로 데이터를 저장한다.
Contiguous Allocation
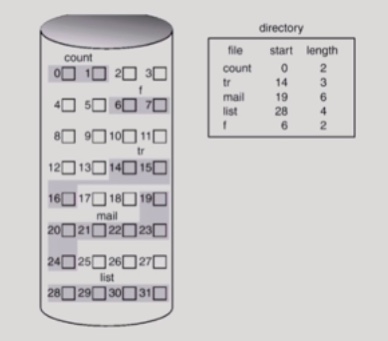
연속할당 방법의 경우 인접한 경우 연속한 숫자와 배열로 값이 들어가는 것이다. directory에는 파일 5개가 들어있고 각각의 meta data를 갖는다. 예를 들면 list 파일의 경우 28번부터 시작해서 4칸을 차지하는 것이다.
· 장점
1) 빠른 I/O가 가능하다.
-> 특히 하드디스크 같은 매체는 헤드가 이동하는 시간이 거의 대부분의 접근시간을 대변한다.
한 번의 이동으로 많은 양의 데이터를 받아올 수 있으므로 시간이 단축된다.
2) 직접 접근이 가능하다.
· 단점
1) 각각 파일의 크기가 균일하지 않기 때문에 비어있는 공간이 발생할 수 있다.(external fragementation)
2) 각 파일이 수정되는 경우 파일의 크기가 변경될 수도 있다.
-> 파일이 커질 것을 대비하여 미리 여분 공간을 만들어둘 수도 있다.(다시 내부조각이 발생하는 문제점이 생긴다.)
Linked Allocation
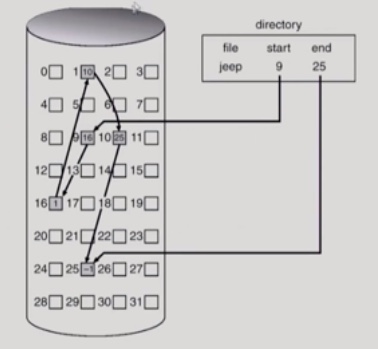
파일의 데이터를 차례로 알려주는 것.
파일의 시작위치만 directory가 갖고 있고 그다음의 위치는 가봐야 알 수 있는 것.
· 장점
1) 외부조각이 발생하지 않는다.
· 단점
1) 직접 접근이 불가능하다.(중간 위치를 보려면 앞에서부터 차례로 다 봐야 함)
2) Realibility 문제: 파일을 구성하는 섹터의 개수가 1000개라고 가정, 섹터 1개에서 문제가 생기면 포인터 유실로 인해 뒷부분을 다 날리게 될 수도 있다.
Indexed Allocation

인덱스 블록을 통해 파일이 어디에 저장되어 있는지에 관한 위치 정보를 기억해 두는 것이다.
· 장점
1) External fragmentation이 발생하지 않는다.
2) Direct access가 가능하다.
· 단점
1) Small file의 경우 공간낭비가 된다.
2) Too large file의 경우 하나의 block로 index를 저장하기 부족하다.
- UNIX 파일시스템의 구조

저장되는 공간을 크게 4가지로 나눌 수 있다.
· Boot block
부팅에 필요한 정보가 들어가는 부분
· Super block
파일 시스템의 총체적인 정보를 담고 있다.
어디가 빈 블록이고 어디가 사용되는 블록인지를 관리하는 부분..
· Inode list
파일 이름을 제외한 파일의 모든 메타 데이터를 저장
(파일의 메타데이터는 파일의 디렉터리에 저장되는데,, 디렉터리가 모든 파일의 메타데이터를 갖는 것은 아님.
즉, 나머지 파일의 메타데이터가 Indode에 저장되는 것이다.)
* 단 파일의 이름은 반드시 directory file에 저장되어 있다.
· Data block
파일의 실제 내용을 보관

- Fat File System
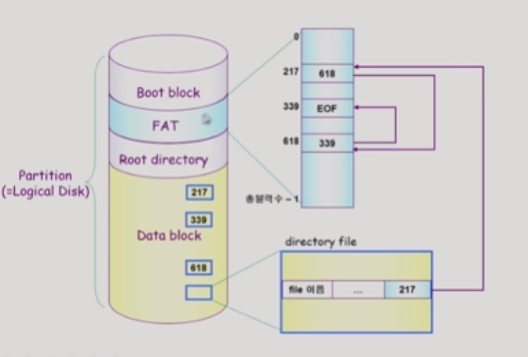
파일의 메타데이터 일부를 FAT에 저장하는데, FAT에는 위치정보만 저장된다.
예를 들어 217번 다음블록의 값을 FAT에 저장하는 것인데, FAT의 크기는 Data block의 개수만큼 생기는 것이다.
- Free Space Management
· Linked list
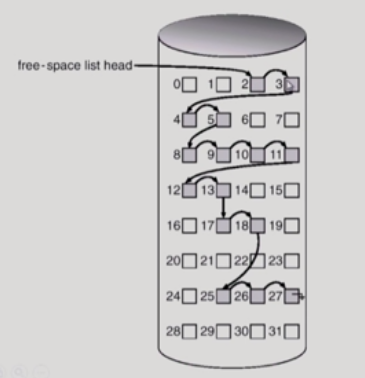
모든 free block들을 링크로 연결한 것이다. 연속적인 가용 공간을 찾는 게 쉽진 않지만
공간의 낭비가 없다는 특징이 있다.
· Linked list
linked list의 방법의 변형이다.
연속적인 빈 block을 찾는데 그리 효과적이지는 않다.
· Counting
프로그램들이 종종 여러 개의 연속적인 block을 할당하고 반납한다는 성질에 착안한다.
- Directory Implementation
디렉터리 파일 밑의 메타 데이터를 관리하는 특별한 파일.. File의 metadata의 보관위치의 경우 디렉터리 내에 직접 보관하지만 디렉터리에는 포인터를 두고 다른 곳에 보관하기도 한다. (Inode, FAT 등이 있다)
· Liner list
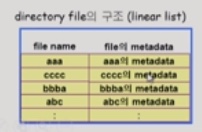
<file name, filed의 metadata>의 list
구현이 간단하다는 특징이 있지만 특정 연산에 대해 많은 시간이 걸린다는 단점이 있다.
그래서 사용할 수 있는 구현 방법이 Hash Table인데.
· Hash Table

특정 범위를 정하는 Hash 함수의 특성을 활용하여 시간을 단축할 수 있다.
단 Collision이 발생한다는 단점도 있다.
- VFS and NFS

· Virtual File System
서로 다른 다양한 file system에 대해 동일한 시스템 콜 인터페이스를 통해 접근할 수 있게 해주는 OS의 layer
· Network File System
분산 시스템에서는 네트워크를 통해 파일이 공유될 수 있음
NFS는 분산환경에서의 대표적인 파일 공유 방법이다.
- Page Cache and Buffer Cache
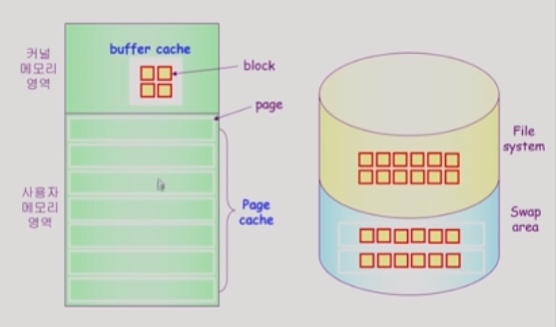
· page cache
프로세스의 주소공간을 구성하는 page가 swap area에 있는지 page cache에 올라와 있는지
· buffer cache
file 데이터가 file system storage에 저장되어 있는지 운영체제에 있는지.
* 최근에는 buffer cache와 page cache가 통합되며 buffer의 단위도 마찬가지로 page 단위를 사용하게 되었다.
· Memory Mapped I/O
File의 일부를 virtual memory에 mapping 시키는 것.
기존 read/write system call과 비교해 볼 수 있다.

좌측의 기존 방법의 경우에는 항상 buffer cache를 거쳐가야 하는 over head가 있지만, 우측 I/O의 경우 운영체제에게 CPU제어권이 넘어가, 미리 값을 전달하므로 보다 단순한 경로를 갖는 것을 알 수 있다.
- Disk Structure
· logical block
디스크의 외부에서 보는 디스크의 단위 정보 저장 공간들이다. 주소를 가진 1차원 배열처럼 취급하며 정보를 전송하는 최소단위이다.
· Sector
logical block이 물리적인 디스크에 매핑된 위치이다.
Sector 0은 최외곽 실린더의 첫 트랙에 있는 첫 번째 섹터이다.
- Disk Management
· physical formatting
디스크를 컨트롤러가 읽고 쓸 수 있도록 섹터들로 나누는 과정이다. 각 섹터는 header + 실제 data + trailer로 구성된다. header와 trailer는 sector number, ECC(Error Cprrecting Code)등의 정보가 저장되며 controller가 직접 접근 및 운영한다.
· Partitioning
디스크를 하나 이상의 실린더 그룹으로 나누는 과정이다.
OS는 이것을 독립적인 disk로 취급한다.
· Logical formatting
파일 시스템을 만드는 것으로 FAT, inode, free space 등의 구조가 포함된다.
· Booting
ROM에 있는 'small bootstrap loader'의 실행
sector 0을 load 하여 실행
sector 0은 'full Bootstrap loader program'
OS를 디스크에서 load 하여 실행
- Disk Scheduling
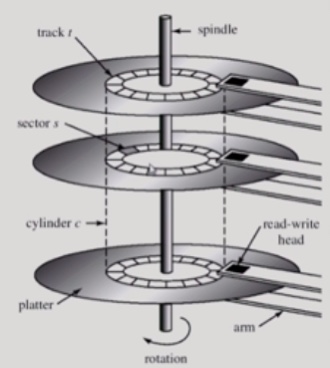
Access time의 구성
· Seek time
헤드를 해당 실린더로 움직이는 데 걸리는 시간
· Rotational latency
헤드가 원하는 섹터에 도달하기까지 걸리는 회전지연시간
· Transfer
실제 데이터의 전송 시간
Disk bandwidth
단위 시간당 전송된 바이트의 수
Access time의 구성
seek time을 최소화하는 것이 목표
Seek time = seek distance
- Disk Scheduling Algorithm
FCFS(First Come First Service)
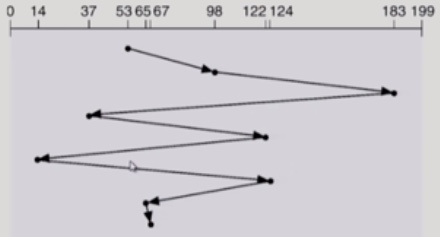
순서대로 이동하기 때문에 비효율적이다.
SSTF(Shortest Seek Time First)
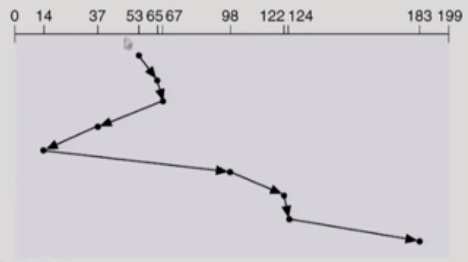
현재 head의 위치에서 가장 가까운 요청을 먼저 처리한다.
SCAN

어떤 요청이 들어왔는지와 상관없이 디스크의 HEAD는 가장 안쪽 위치에서 바깥쪽 위치로 요청을 해결하는 것. 중간에 새로운 요청이 있으면 처리하고 지나간다. 다른 한쪽 끝에 도달하면 역방향으로 이동하며 오는 길목에 있는 모든 요청을 처리하며 다시 반대쪽 끝으로 이동한다.
C-SCAN


헤드가 한쪽 끝에서 다른 쪽 끝으로 이동하며 가는 길목에 있는 모든 요청을 처리.
다른 쪽 끝에 도달했으면 요청을 처리하지 않고 곧바로 출발점으로 이동한다.
SCAN보다 균일한 대기 시간을 제공한다는 특징이 있다.
- Disk Scheduling Algorithm의 결정
SCAN, C-SCAN 및 그 응용 알고리즘은 LOOK, C-LOOK 등이 일반적으로 디스크 입출력이 많은 시스템에서 효율적인 것으로 알려져 있다. File의 할당 방법에 따라 디스크 요청이 영향을 받는다. 디스크 스케줄링 알고리즘은 필요한 경우 다른 알고리즘으로 쉽게 교체할 수 있도록 OS와 별도의 모듈로 작성되는 것이 바람직하다.
- Swap Space Management
Disk를 사용하는 두 가지 이유
· memory의 volatile 한 특성 -> file system
· 프로그램 실행을 위한 memory 공간의 부족 -> swap space(swap area)
- RAID
RAID(Redundan Arrary Independent Disks)
여러 개의 디스크를 묶어서 사용하는 것이다.
RAID를 사용하는 이유는 여러 디스크에 block내용을 분산 저장하고 병렬적으로 읽어오기 때문에 디스크 처리 속도가 향상된다.
또한 동일 정보를 여러 디스크에 중복으로 저장하기 때문에 신뢰성이 향상된다.
운영체제 강의를 다 들었다. 초반 강의에 비해 점점 어려워져서 이걸 듣는 게 맞나..? 생각하긴 했지만 이번 강의의 경우 엄청나게 깊게 공부하자고 하기보단 한번 둘러보자는 느낌이었기에 끝가지 들었다,
운영 체제 책도 함께 공부하며 강의를 다시 들어볼 생각이다. 기분 탓인진 모르겠지만 운영체제 공부 잠깐 했다고 컴퓨터를 볼 때 내가 A라는 행동을 하면 컴퓨터 뒤에선 어떤 작업이 일어날까? 하는 생각도 했다.
물론 생각만 했다. 답은 찾지 못했다. 이젠 10월이 다 지나고 11월이 다가온다. 11월 계획도 잘 세워서 군대 안에서의 시간을 누구보다 알차게 사용할 생각이다.
'Computer Science > 운영체제' 카테고리의 다른 글
| [운영체제] 군대에서 공부하기 Week3 (0) | 2023.10.15 |
|---|---|
| [운영체제] 군대에서 공부하기 Week2 (3) | 2023.10.08 |
| [운영체제] 군대에서 공부하기 Week1 (1) | 2023.10.01 |


